
Second place in the ACM SIGMOD 2015 programming contest
Last spring was a really exciting period! Me (EPFL), and two more PhD students from the SAP HANA Database Campus team, Ismail Oukid (TU Dresden) and Ingo Müller (Karlsruhe Institute of Technology), participated in the ACM SIGMOD 2015 programming contest, with the team name “SimpleMind”. We scored 2nd place globally! It was a really interesting experience, we honed our database design skills and produced high-quality code. You can download our team’s poster, presentation, and source files here or here. Next, I provide a description of our solution, which is also available at the SAP SCN.
The task
The context of the programming contest was about optimistic concurrency control. The contestants are called to implement an application that, given a sequence of transactions (insert and/or delete statements) and a sequence of validation queries (select statements on the data modified by a range of transactions), can detect for each validation whether it conflicts or not (i.e., whether it produces a non-empty result or not).
The data sets provided by the programming contest organizers were of three sizes (small, around 90MB, medium, around 900MB, and large, around 9GB). Our team analyzed the data sets to figure out statistics about the workload. The most significant statistics were that 80% of the messages are validations, less than 10% of the validations resulted in a conflict, 80% of the transactions only touch a single relation, 90% of the validation predicates are an equality predicate, and that 50% of the validation queries use the primary key columns of the relations.
Data structures for transaction processing
Our team came up with a solution inspired from the SAP HANA database design: read-optimized data structures for fast analytics, coupled with write-optimized data structures for transaction processing. Due to the nature of the workload, the processing can be separated into write-optimized and read-optimized phases. For the write-optimized phase, which includes the transaction processing, data structures were used that can easily incorporate the changes of new transactions, and keep a history of their changes.
For each relation, our team keeps a row store of valid and deleted rows. A primary key (PK) index (PK -> valid rows) is used for fast updates. They also keep a two-level “history index” (transaction ID -> list of pointers to modified rows -> row) for fast validation of single rows.
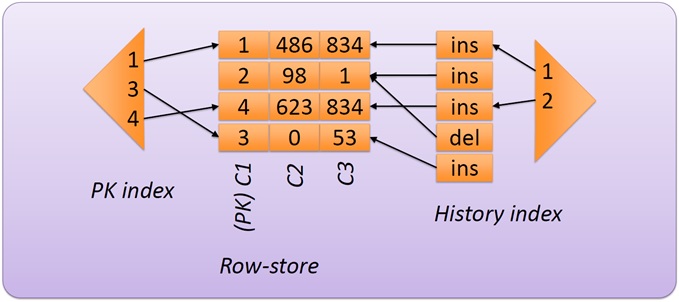
Data structures for validation processing
The modified rows from the transaction phase are converted periodically to a column-wise format, to facilitate the read-optimized phase of validation processing. Additional metadata is built. First, a single level “history index” (tx ID -> offset of first modified row) is built. Second, 8-bit fingerprint columns are built to realize super fast approximate scans. Finally, a sample of distinct values per column is kept to estimate the selectivity of validation queries.
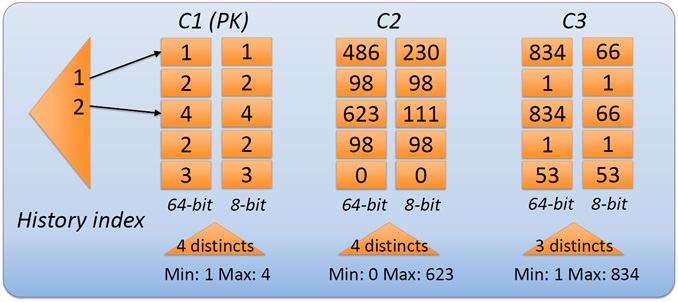
Validation processing
The validation phase is the most crucial and computation-intensive part of the execution of the workload. The workflow of the validation phase is depicted below. The phase is composed by simple nested loops that go through (1) each validation in the request stream, (2) each query in the validation, (3) each predicate in a query, and finally (4) each row in the transaction range (primarily by scanning the aforementioned history data structures).
For a query, the system gets the relevant transaction range from the history index. Then, it evaluates the predicates of the query, to see if any one matches modified rows, in which case the validation results in a conflict. If no modified rows are matched for the whole validation, there is no conflict.
For each evaluated predicate, a scan is performed, whose result is a filter for the next predicate’s scan. Several heuristics are employed to evaluate very selective predicates first. For example, equality predicates on primary key columns are preferred, as they are the most selective, otherwise the sample of distinct values of the columns’ metadata is used to order them. For equality predicates, the scan first performs a fast SIMD scan on the fingerprint columns to create the filter for the full scan on the history. The SIMD scan can filter out quickly many rows.

Bulk-synchronous parallelization
To use all available computing resources, our team chose a form of bulk-synchronous parallelism. The row-store is hash-partitioned (by the PK). Each thread only executes transactions of its partition. Validations are queued. On a flush request (given by the driver of the competition organizers to print the results of the validations seen so far), the partitions are merged into the column-store. Afterwards, threads process validations from the queue, now accessing all read-optimized data structures, and the column-store, in a read-only fashion. As another optimization, additional flushes are artificially performed to overcome the slow speed of the driver application.
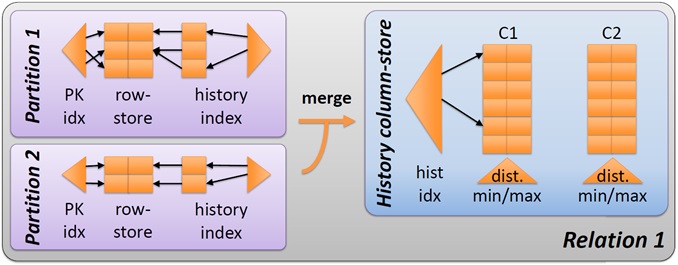
Implementation details
In the spirit of their team name, our team kept the implementation simple, consisting of just 1268 lines of code (according to sloccount). This is really small, compared to the 165 lines of code of the reference implementation given by the organizers. For parallelism, OpenMP is used, with some intertwined boost threads to implement additional validation threads. The code has extensive use of the STL and C++11. The code is indented with 4 spaces.
Some notable tweaks that gave more than 10% performance gain were: (a) “infinite” vectors to avoid allocation overheads, (b) branch-free scans, (c) the use of boost::flat_map for the history index, (d) recycling allocated memory, and (e) simple scan selection mechanism.
Runtime break-down
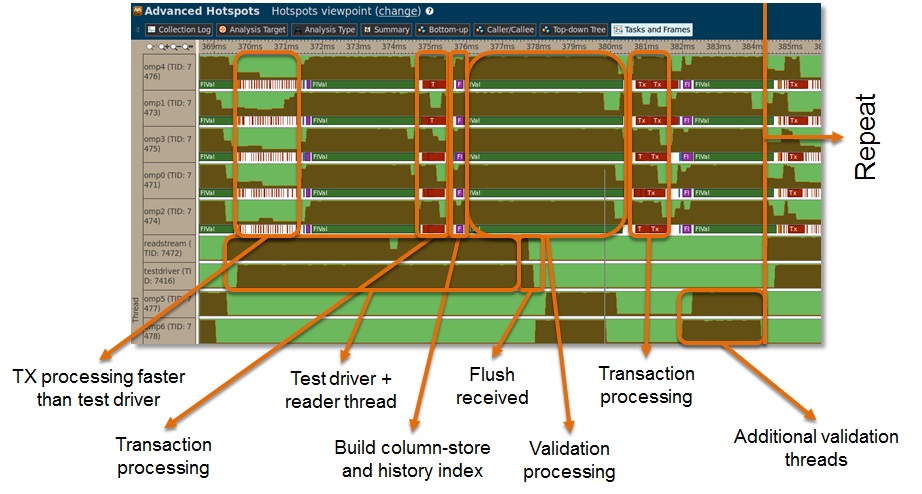
To validate the performance, and find any hotspots that need improvement, our team used the Intel VTune Amplifier tool to analyze our performance. They integrated VTune’s ability to detect custom tasks, and could thus easily mark the different phases of the application (transaction processing, merge phase, validation processing, etc.) to visualize them with VTune. The screenshot below shows the execution flow of their solution.
Some noteworthy comments about the break-down are the following. First, the transaction processing phase is faster than the organizers’ test driver. An artificial or real flush to merge the history to the read-optimized data structures, plus the validation phase, can eliminate these “white spots”. After sufficient traffic has arrived, the transaction processing phase does not have “white spots”. Only after the test driver needs to transmit more traffic to us, we see the white spots re-appearing. Furthermore, two additional threads are used for validation, while the reader stream and the test driver are inactive, in order to fully utilize these hardware contexts as well.
Conclusion
The solution of our team demonstrates the efficiency of concepts drawn from SAP HANA experience. It consists of a write-optimized phase for processing transactions, appending continuously to a row-store. Then the partitioned history is merged into read-optimized data structures, building a column-store as well. The validation phase then uses the read-optimized data structures to evaluate the queries, using full parallelism, SIMD-optimized scans, and several heuristics such as opting to scan more selective columns first.
All-in-all, the SIGMOD programming contest was a challenging experience with many advantages. Apart from worldwide visibility, the contestants can apply practical concepts and innovative research into building a prototype database system from the ground up.
Leave a comment